论文标题:通过强化学习,实现自行车的动态调配
原文链接
参考资料:
莫凡的个人网站
1 | 论文题目:Dynamic Bike Reposition: A Spatio-Temporal Reinforcement Learning Approach |
论文作者详细介绍:
Yenxin Lin是香港科技大学的学生
杨教授现任香港科技大学计算机科学与工程系讲师。他的研究兴趣包括机器学习,人工智能和数据挖掘。
京东金融副总裁,首席数据科学家。 主要任务是利用大数据和人工智能技术解决交通和城市规划等城市挑战。
1.Introduction
这篇文章所讲的自行车的动态调配,并不是指的共享单车,而是下图所示的比较传统的自行车站,这主要是因为课题研究的时候,共享单车还没有火,并且论文所使用的数据是英国的数据,那边没有共享单车。
在整个地区的自行车站点里,总是会有一些站点缺少自行车,而有些站点的自行车过多,一般需要通过运输的方式将自行车进行调配,这篇论文解决的就是如何调配,也就是应该从哪一个站点运输多少辆自行车到其他某个站点去。
2.Our approach
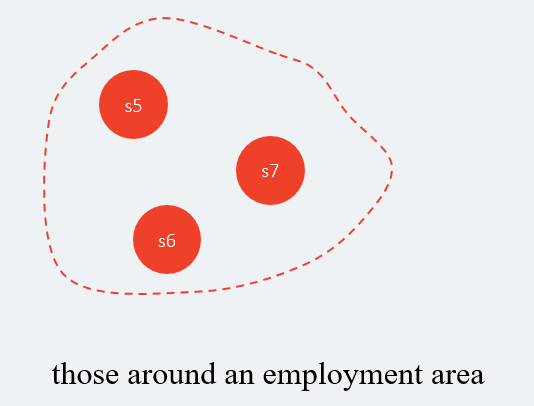
一个市的面积是很大的,我们不可能在整个市的所有自行车站点之间进行自行车的调配,这是不必要的,同时也会浪费大量的人力、物力、财力,所以我们应该减少,调配自行车的范围,比如现在有7个自行车站点,我们不会在这7个站点之间进行自行车的调配。
在这7个站点,我们会根据规则对其进行划分,规则如下:
1 | 1.两个站点之间的距离要接近,相隔太远是无法划分到一个区域里面的。 |
最后这7个站点,可以根据这些规则划分为两个区域(这里只是举个例子):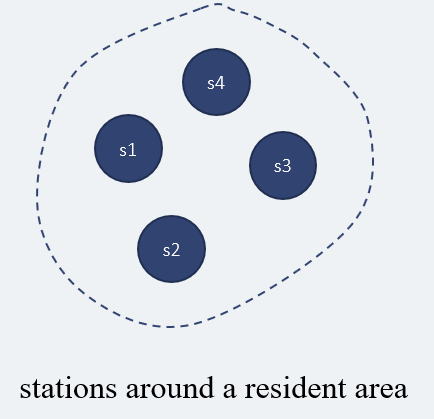
因为这些区域地理位置相近,且行车轨迹也大致相同,现在我们将分好的区域作为单位去考虑自行车调配的问题,但是即便如此,从城市的角度来看,我们也不需要在所有不同的区域之间进行自行车的调配。比如在下面的上海地图中,上面的圆圈表示的就是区域,人们一般不会从松江骑个车到静安区,所以考虑整个城市所有区域的调配是不必要的。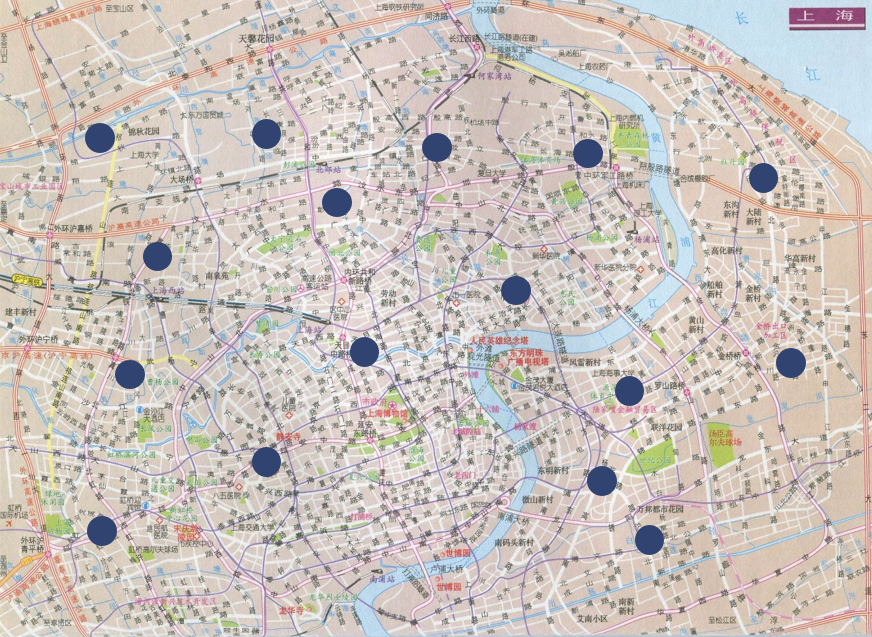
所以,我们可以将区域分成不同的组,只在组之间进行调配,这样可以大大的节省下资源。显然,现在的问题,就是应该如何去分组保证调配的合理。
区域分组的过程分成了三个步骤:
1 | Step 1:根据这两个区域之间的通勤记录进行连接,通行频率高于给定阈值的就进行连接。 |
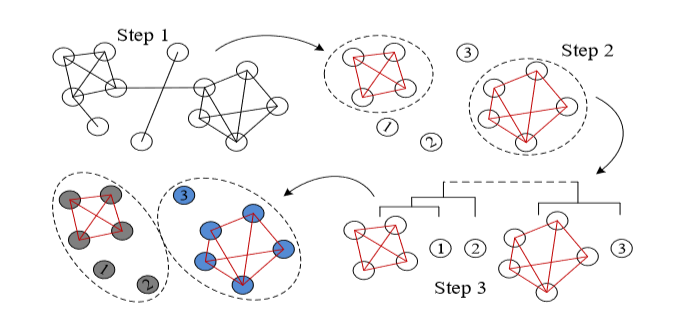
现在已经完成了区域分组,我们只会在组内,进行自行车的调配,组与组之间的调配,我们是忽略不计的。
到现在,要解决的问题就是,如何在组内进行自行车的调配,也就是找到调配自行车的策略,这篇论文使用的就是强化学习的方法。所以下面简要的介绍一下,强化学习是什么: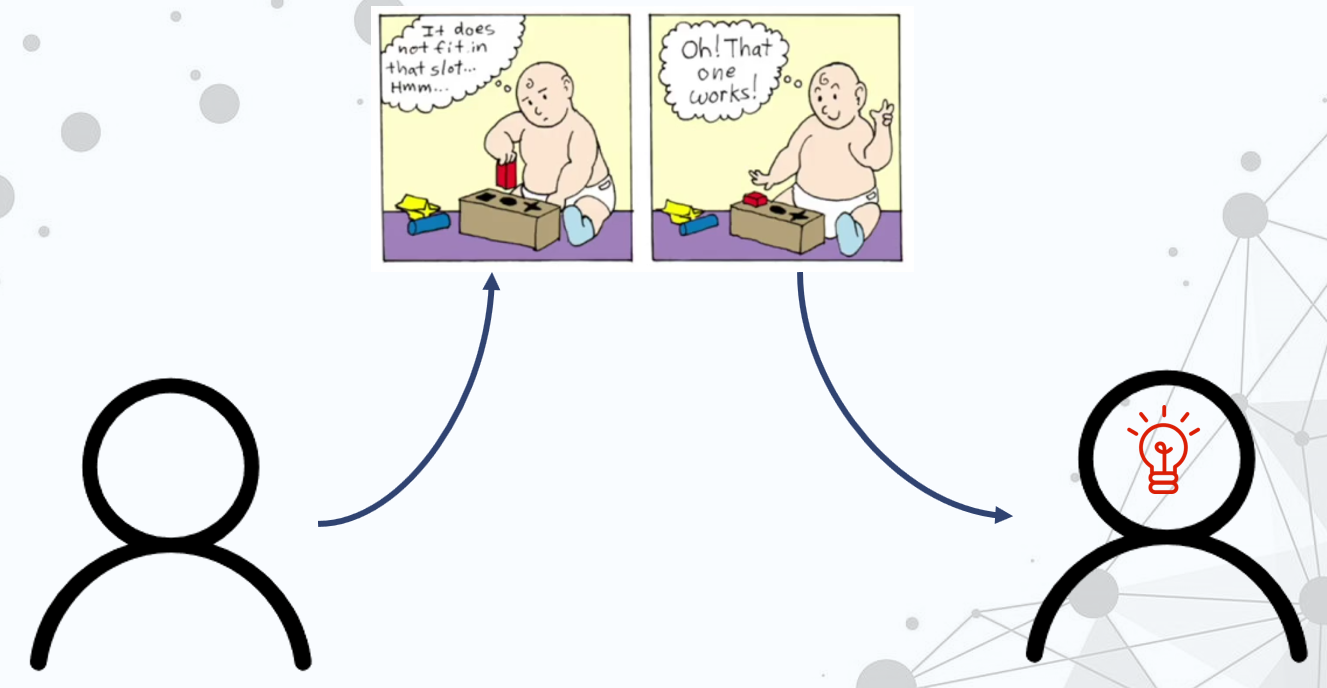
强化学习就是像图中的小朋友一样,一开始什么都不懂,然后经过不断的试错,掌握了知识,找到了正确的方法。
强化学习就像是一个人,第一次见到火,他不知道这是什么。
但是他感觉到了温暖,所以他觉得火是好的,并且想要更靠近火。
在触碰了之后,被火给烫到了,他学会了不能离的太近,也不能去触碰火。
在经过这一学习过程后,他学会了,要适当的保持距离,不能触碰。
强化学习就如下图所示,我们做出某些行为,得到反馈,我们对环境进行观察,最后不断学习的过程。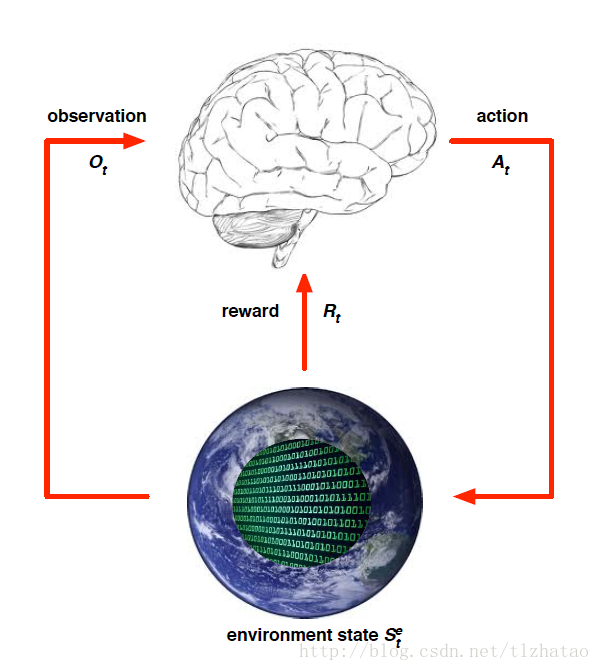
强化学习的分类方法有很多,这里的分类就是按是否基于模型来分类的,下面进行详细的介绍。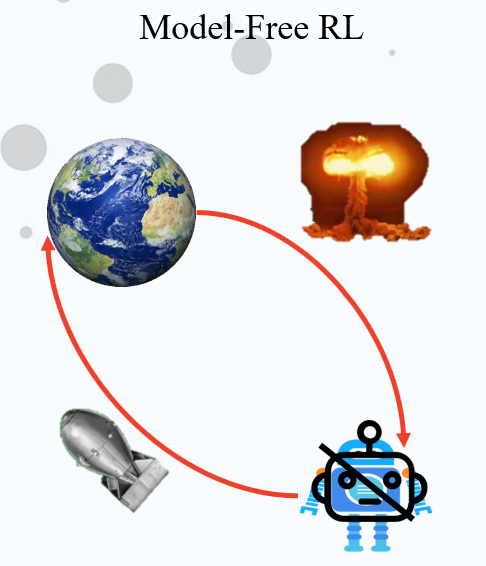
不基于模型的强化学习,就是只能通过现有的观察来得出结论,进行学习。比如这里有一个机器人,它想知道在地球上扔一个原子弹会发生什么,它这样做了,然后把自己给炸死了。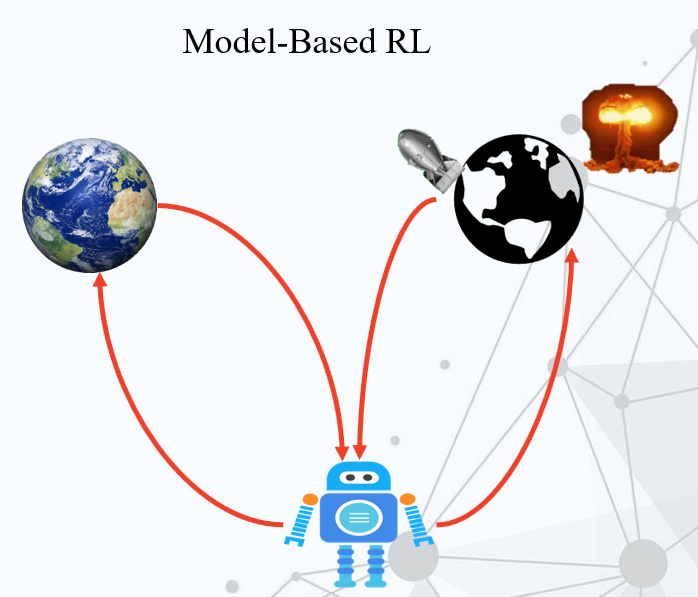
基于模型的强化学习,现在这个机器人也要做同样的事情,但是它是基于模型的,所以它拥有了想象力,它可以再做出一个地球的模型,然后在这个假的地球上做实验,得出结论。
Model-Free RL只能够做一步,看看反应,然后再做,最后完成学习的过程,它是没有想象力的。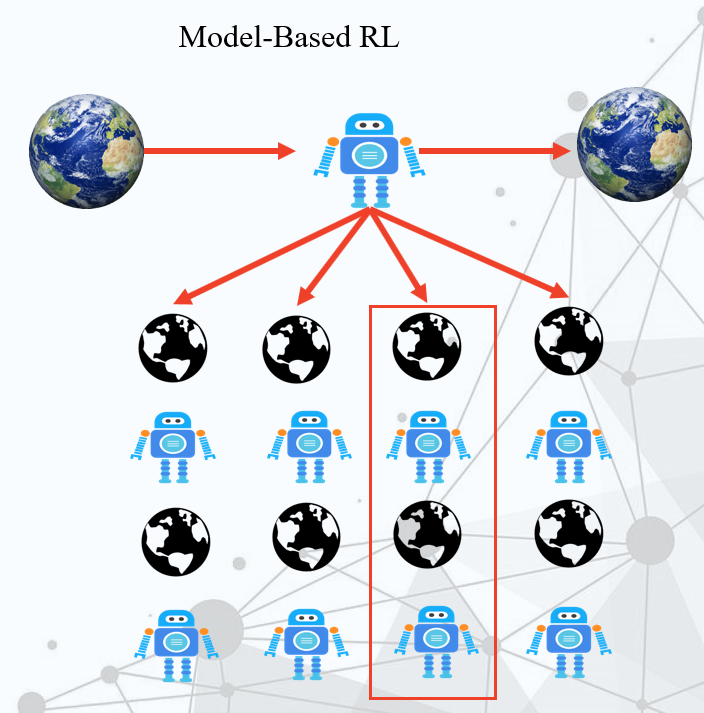
Model-Based RL就是可以想象出做了之后的事情,然后可以从中选择一个去执行。
下面是用神经网络实现的强化学习过程,输入现在的状态和动作,神经网络会根据反馈给这个动作打一个分。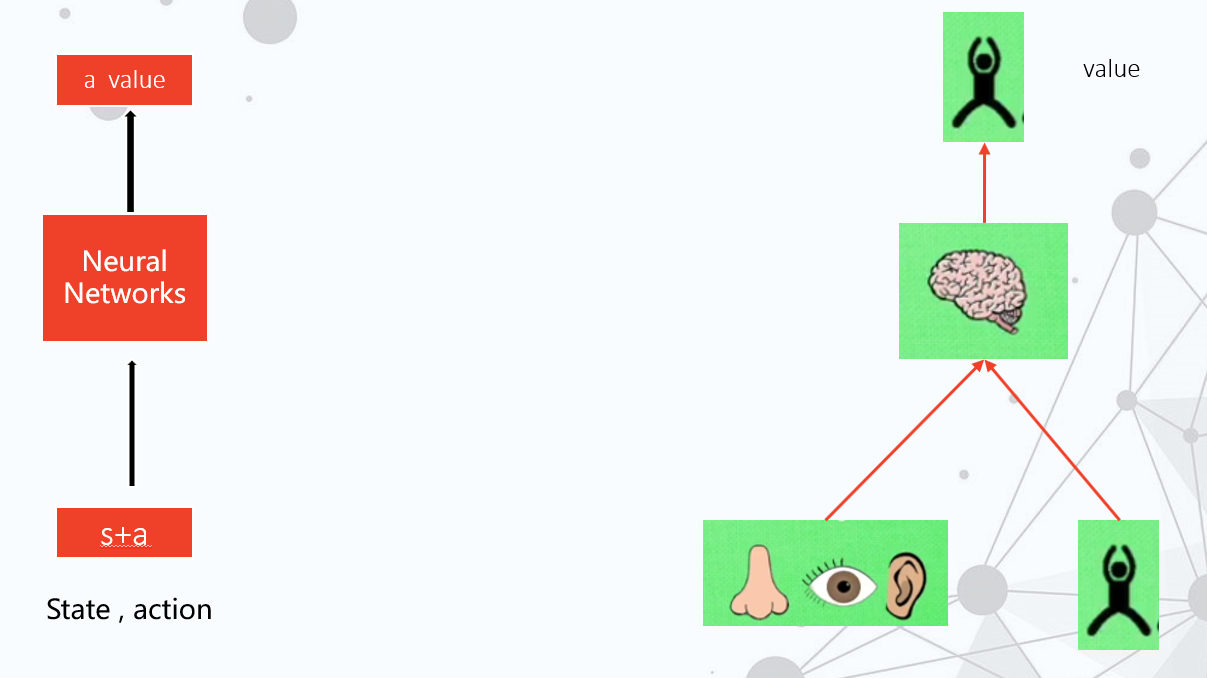
回到论文中来,我们会利用强化学习,来完成自行车调配问题,输入现在各自行车站点的信息,比如数量,和运输车的信息,再还要输入可能会做的许多的调配行动,选择神经网络里面分数最高的一个去执行。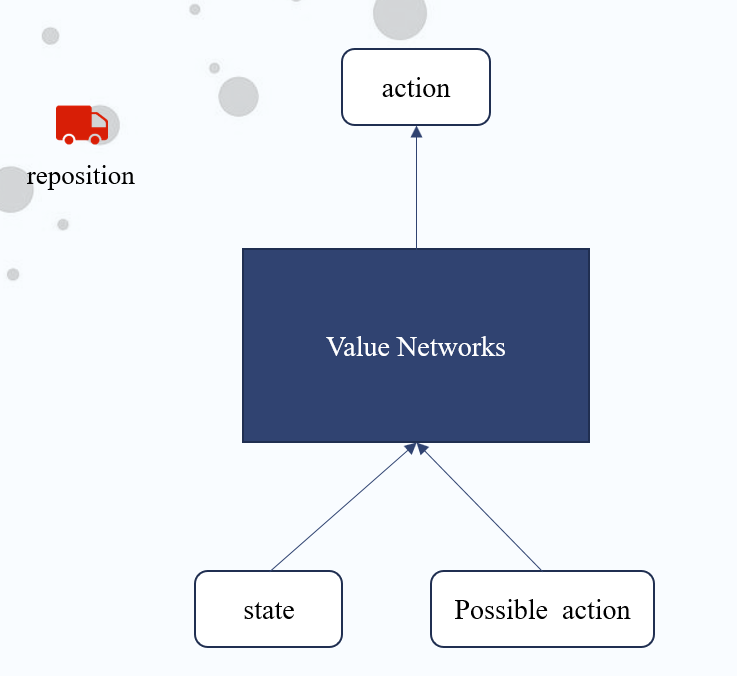
为了让神经网络能判断的更准确,还加入了一个模拟器,用来模拟自行车的归还需求,以及租界需求,当然是在一定的时间里面进行的模拟。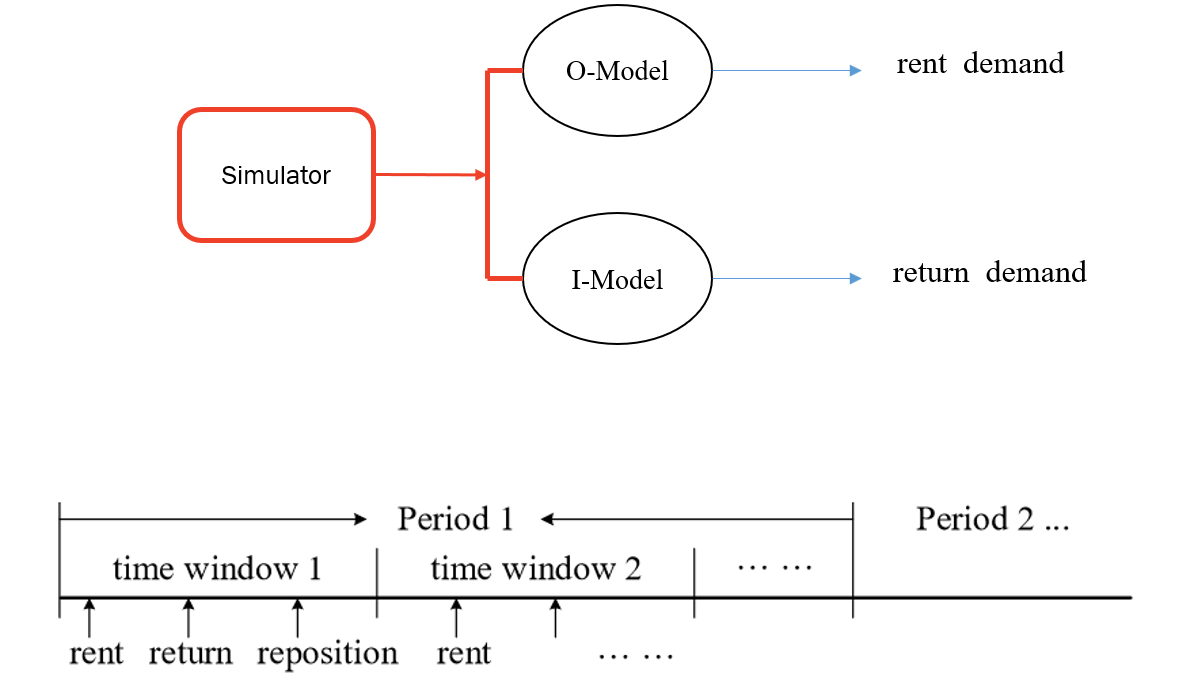
在这个过程里,根据神经网络的判断进行自行车的运输,之后会得到反馈,这些记录都存放在样本池里面,用来供神经网络学习,使其判断的更准确。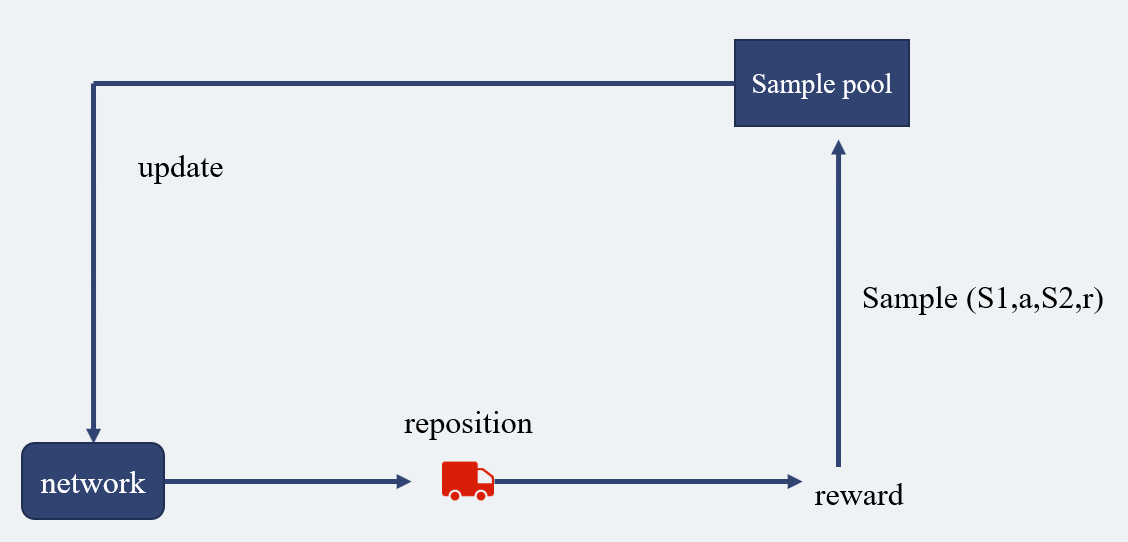
自行车的动态调配过程:
1 | 1.Cluster : 在图中的Region Clusters部分,也就是上文所讲的分组过程,我们只会在组内进行自行车的调配。 |
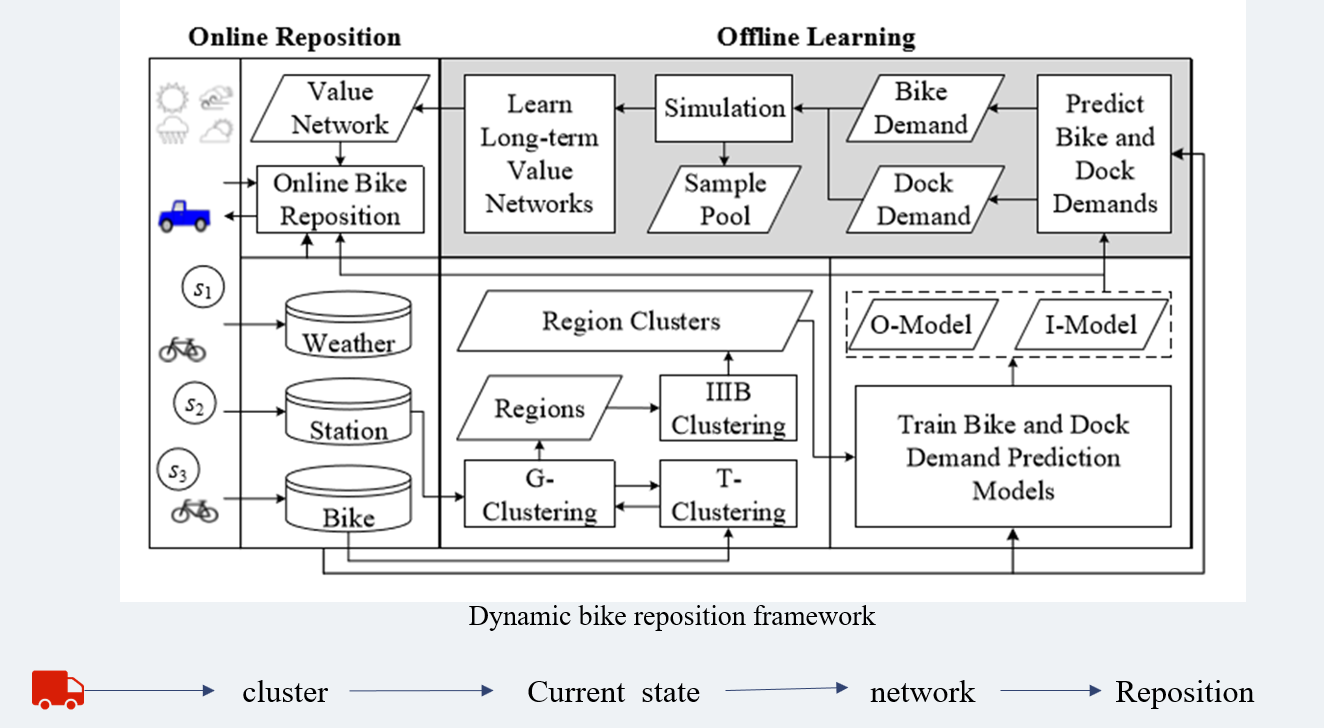
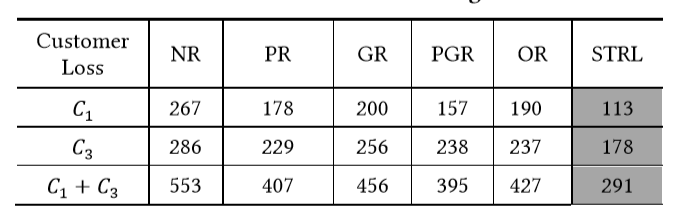
3.Experiment
图中的数字表示的是顾客减少量,也就是没有骑到自行车的人,从图中我们可以看到,使用STRL也就是本文所介绍的方法,顾客的损失量是最少的,也即是效果最好。